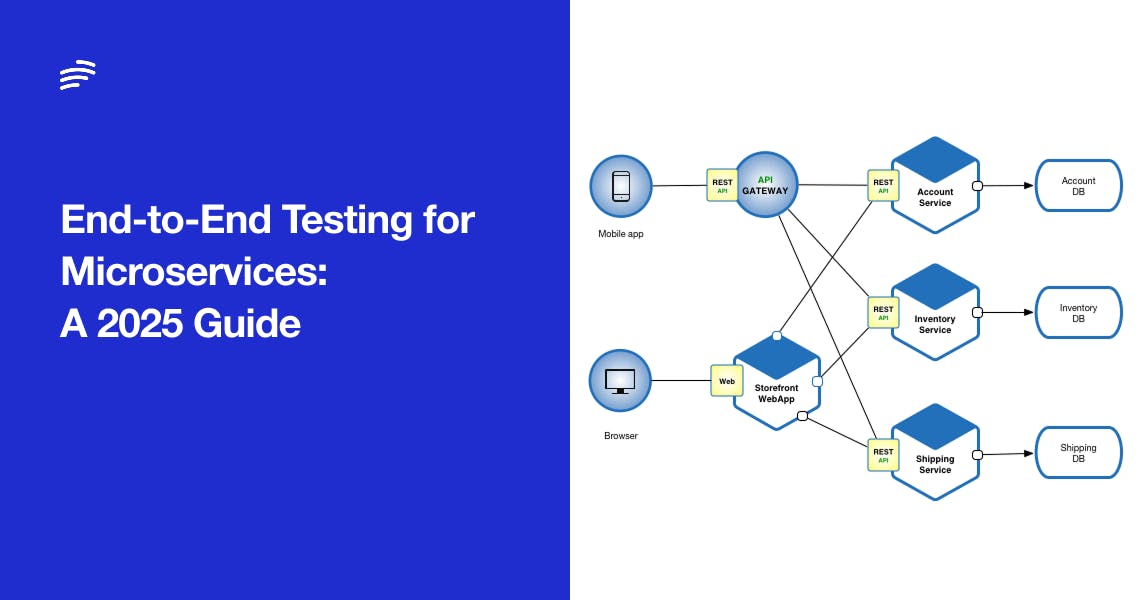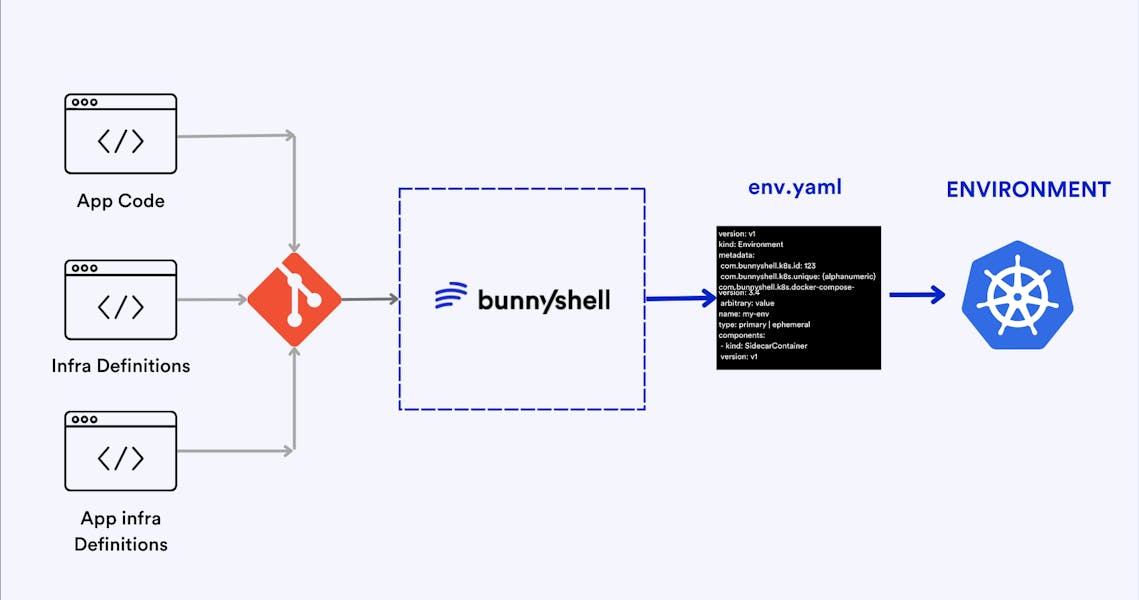
Ephemeral Environments for CI/CD (GitOps) Pipelines
Historically, we only run unit and integration tests in our CI pipeline. But at times, we also face issues in production that could have been caught during development had our testing environment resembled our production environment and we performed testing and deployment in that test environment.
Testing your application in a production-like environment can help you catch bugs early in the development lifecycle and increase the overall quality of the shipped product. However, setting up your CI/CD pipeline in a way that allows you to set up ephemeral production-like environments is not a trivial undertaking.
In this article, we’ll see how to use Kubernetes to create ephemeral environments that look like production in a cost-effective way.
Setup
We’ll be showcasing two approaches. The first is to have a shared Kubernetes cluster, where each ephemeral environment is a separate namespace but the underlying cluster is the same. The second is to have a separate cluster for each ephemeral environment.
The first approach is more cost-effective, while the second provides more separation between different environments if that is needed for compliance.
We’ll be using GitLab for source control management and Google Kubernetes Engine to deploy our ephemeral environments.
Prerequisites
To follow along with the code examples, you will need:
- A GitLab account (free trial)
- Google Cloud Platform (90-day free trial with $300 in free credits)
- Gcloud set-up locally or Google Cloud Shell
- Node.js web application (clone from here)
Demo Setup
First, you’ll need to set up the necessary Google Cloud resources needed for this post.
**Service Account **
Create a service account to use in your pipeline to interact with GCP:
gcloud iam service-accounts create ci-cd-gitlab --description="This account is used for ephemeral CI/CD example." --display-name="ci_cd_gitlab"
Next, give permissions to this account:
- Service Account User
- Artifact Registry Administrator
- Kubernetes Engine Admin
For the purpose of this post, we are using slightly higher permissions, but in the production setting, you should adjust the permissions according to your setup.
Now, you can download the JSON key for this service account; you will use this file to set up variables for your CI pipeline.
Note that the content of the JSON file is sensitive, so create a variable called GOOGLE_JSON_KEY in your GitLab pipeline and paste the content there. This will allow you to use the key without putting it in your repository.
**Google Artifact Registry **
Create a Docker repository in Artifact Registry, which you’ll use to push your web application Docker image. We have created a repository named ephemeraldemo, which we will use throughout this demo.
Variables for the CI Pipeline
Instead of hard-coding these variables for use in our CI pipeline, we’ll refer to them from pipeline variables.
You’ll need to create the following variables for use in subsequent steps:
- GOOGLE_KEY_JSON: The JSON key file configured above
- PROJECT_ID: GCP Project ID
- REGION: Region in which your cluster and other resources are configured, e.g., us-central1
- REPOSITORY_NAME: Name of the Artifact Repository created above
- ZONE: Availability Zone in which your cluster and other resources are configured, e.g., us-central1-c
Ready to Automate Ephemeral Environments for your CI/CD Pipeline?
Bunnyshell automatically creates ephemeral environments on every pull request and tears it down with every merge close.
Sample Workflow
This sample workflow shows you how to achieve an ephemeral production-like test environment using Kubernetes.
First, you need to understand what the workflow will look like for both a shared cluster and an isolated cluster.
Shared Cluster Approach
- A developer creates a merge request for changes.
- The build triggers and creates a Docker image for the latest changes and pushes it to Artifact Registry by tagging it with the current branch name.
- The pipeline will create a new namespace in the shared Kubernetes cluster using the branch name.
- The application will be deployed to the namespace created in Step 3 using the Docker image built in Step1.
- The pipeline will give the address of the newly created load balancer to access the web application.
- The namespace will be cleaned up when the reviewer merges the request.
Isolated Cluster Approach
- A developer creates a merge request for changes.
- The build triggers and creates a Docker image for the latest changes and pushes it to Artifact Registry by tagging it with the current branch name.
- The pipeline creates a new Kubernetes cluster using the branch name.
- The application will be deployed to the default namespace in the newly created cluster in Step 3 using the Docker image built in Step 1.
- The pipeline will give the address of the newly created load balancer to access the web application.
- The namespace will be cleaned up when the reviewer merges the request.
Both of these workflows are captured in the following deploy_gke.sh script, which you will use in the .gitlab-ci.yml file to set up the CI pipeline.
First, let’s take a look at the content of deploy_gke.sh file:
1#!/bin/bash
2
3set -xe
4
5CLUSTER_TYPE=$1
6CLUSTER_NAME=$2
7BRANCH_SLUG=$3
8REGION=$4
9ZONE=$5
10PROJECT_ID=$6
11DOCKER_IMAGE=$7
12
13
14create_cluster(){
15 gcloud beta container --project "$PROJECT_ID" \
16 clusters create "$CLUSTER_NAME" \
17 --zone "$ZONE" \
18 --no-enable-basic-auth \
19 --cluster-version "1.22.8-gke.202" \
20 --release-channel "regular" \
21 --machine-type "g1-small" \
22 --image-type "COS_CONTAINERD" \
23 --disk-type "pd-standard" \
24 --disk-size "100" \
25 --metadata disable-legacy-endpoints=true \
26 --scopes "https://www.googleapis.com/auth/devstorage.read_only","https://www.googleapis.com/auth/logging.write","https://www.googleapis.com/auth/monitoring","https://www.googleapis.com/auth/servicecontrol","https://www.googleapis.com/auth/service.management.readonly","https://www.googleapis.com/auth/trace.append" \
27 --max-pods-per-node "110" \
28 --num-nodes "3" \
29 --logging=SYSTEM,WORKLOAD \
30 --monitoring=SYSTEM \
31 --enable-ip-alias \
32 --network "projects/$PROJECT_ID/global/networks/default" \
33 --subnetwork "projects/$PROJECT_ID/regions/us-central1/subnetworks/default" \
34 --no-enable-intra-node-visibility --default-max-pods-per-node "110" \
35 --no-enable-master-authorized-networks \
36 --addons HorizontalPodAutoscaling,HttpLoadBalancing,GcePersistentDiskCsiDriver \
37 --enable-autoupgrade \
38 --enable-autorepair \
39 --max-surge-upgrade 1 \
40 --max-unavailable-upgrade 0 \
41 --enable-shielded-nodes \
42 --node-locations "$ZONE"
43}
44
45create_isolated_cluster() {
46 echo "Checking if the cluster $CLUSTER_NAME already exists..."
47 cluster_exists=`gcloud container clusters list --zone $ZONE | grep $CLUSTER_NAME | wc -l`
48 if [ "$cluster_exists" -eq 0 ]
49 then
50 echo "Cluster doesn't exist. Creating the cluster"
51 create_cluster
52 else
53 echo "Cluster already exists"
54fi
55}
56
57
58fetch_cluster_credentials(){
59 echo "Fetching cluster credentials..."
60 gcloud container clusters get-credentials $CLUSTER_NAME --zone $ZONE
61}
62
63create_namespace() {
64 echo "Creating isolated namespace $BRANCH_SLUG inside the cluster $CLUSTER_NAME"
65 namespace_exists=`kubectl get namespaces | grep $BRANCH_SLUG | wc -l`
66 if [ "$namespace_exists" -eq 0 ]
67 then
68 echo "Namespace doesn't exists. Will create a new namespace $BRANCH_SLUG"
69 else
70 echo "The namespace already exists. Recreating..."
71 kubectl delete namespace $BRANCH_SLUG
72 fi
73
74 kubectl create namespace $BRANCH_SLUG
75}
76
77
78deploy_resources() {
79 sed -i "s*DOCKER_IMAGE*$DOCKER_IMAGE*g" k8s/deployment.yaml
80 if [ $CLUSTER_TYPE = "SHARED" ]; then
81 kubectl apply -n $BRANCH_SLUG -f k8s/*.yaml
82 else
83 kubectl apply -f k8s/*.yaml
84 fi
85}
86
87wait_for_ip(){
88 external_ip=""
89 while [ -z $external_ip ]; do
90 echo "Waiting for end point..."
91 if [ $CLUSTER_TYPE = "SHARED" ]; then
92 external_ip=$(kubectl get svc app-lb -n $BRANCH_SLUG --template="{{range .status.loadBalancer.ingress}}{{.ip}}{{end}}")
93 else
94 external_ip=$(kubectl get svc app-lb --template="{{range .status.loadBalancer.ingress}}{{.ip}}{{end}}")
95 fi
96 [ -z "$external_ip" ] && sleep 10
97 done
98 echo 'Your preview app is available at : ' && echo $external_ip
99}
100
101
102if [ $CLUSTER_TYPE = "SHARED" ]; then
103 echo "Cluster type is $CLUSTER_TYPE, assuming cluster exists and deploying the resources"
104 fetch_cluster_credentials
105 create_namespace
106 deploy_resources
107 wait_for_ip
108elif [ $CLUSTER_TYPE = "ISOLATED" ]; then
109 echo "Cluster type is $CLUSTER_TYPE. Cluster will be created (if doesn't exist)"
110 create_isolated_cluster
111 fetch_cluster_credentials
112 deploy_resources
113 wait_for_ip
114else
115 echo "ERR : Unknown CLUSTER_TYPE=$CLUSTER_TYPE"
116fi
117You can refactor the create_cluster function in this script to change the characteristics of your isolated cluster. This script takes the following parameters:
- CLUSTER_TYPE: The switch to configure a SHARED or ISOLATED cluster
- CLUSTER_NAME: Name of the cluster in case CLUSTER_TYPE is SHARED
- **BRANCH_SLUG: **Name of the branch
- **REGION: **Region in which to deploy/find the Kubernetes cluster
- **ZONE: **Zone in which to deploy/search for Kubernetes cluster
- **PROJECT_ID: **GCP project ID
- DOCKER_IMAGE: The URL of the Docker image pushed to Artifact Registry
Next is the .gitlab-ci.yml file. This file configures the CI pipeline for your repository. We configure two steps for building and deploying; these only run for commits when you raise a merge request (MR):
1stages:
2- build
3- deploy
4
5variables:
6 IMAGE_NAME: "helloworld-node"
7
8docker-build:
9 # Use the official docker image.
10 image: docker:latest
11 stage: build
12 services:
13 - docker:dind
14 before_script:
15 - echo "$GOOGLE_KEY_JSON" > key.json
16 - cat key.json | docker login -u _json_key --password-stdin https://${REGION}-docker.pkg.dev
17 script:
18 - REGISTRY_URL="$REGION-docker.pkg.dev/$PROJECT_ID/$REPOSITORY_NAME/$IMAGE_NAME"
19 - DOCKER_IMAGE="${REGISTRY_URL}:${CI_COMMIT_REF_SLUG}"
20 - docker build -t $DOCKER_IMAGE .
21 - docker push $DOCKER_IMAGE
22 rules:
23 - if: $CI_PIPELINE_SOURCE == "merge_request_event"
24 - if: $CI_COMMIT_BRANCH && $CI_OPEN_MERGE_REQUESTS
25 when: never
26
27deploy-preview:
28 image: google/cloud-sdk
29 stage: deploy
30 before_script:
31 - echo "$GOOGLE_KEY_JSON" > key.json
32 - gcloud config set project $PROJECT_ID
33 - gcloud auth activate-service-account --key-file key.json
34 - gcloud auth configure-docker us-central1-docker.pkg.dev
35 - REGISTRY_URL="$REGION-docker.pkg.dev/$PROJECT_ID/$REPOSITORY_NAME/$IMAGE_NAME"
36 - DOCKER_IMAGE="${REGISTRY_URL}:${CI_COMMIT_REF_SLUG}"
37 - chmod 777 deploy_gke.sh
38 script:
39 - ./deploy_gke.sh ISOLATED $CI_COMMIT_REF_SLUG $CI_COMMIT_REF_SLUG $REGION $ZONE $PROJECT_ID $DOCKER_IMAGE
40 rules:
41 - if: $CI_PIPELINE_SOURCE == "merge_request_event"
42 - if: $CI_COMMIT_BRANCH && $CI_OPEN_MERGE_REQUESTS
43 when: neverYou can also configure other steps, such as unit and integration tests that run on every commit. However, creating Docker images and deploying them on every commit in every branch is not really a cost-effective and scalable approach.
You only deploy the changes when an MR is raised. This allows the reviewer to go over the changes in a production-like environment before accepting your changes. The rules section in the .gitlab-ci.yml file for each step configures a step to run only when the commit is for a merge request.
The final bit in this workflow is the Kubernetes resource YAML files. You can find these in the k8s folder in the repository. For the purpose of this example, it's a simple deployment exposed via a load balancer service.
If you have Kubernetes in production, you must already have YAML resources that you can reference. You can also use your existing tooling to deploy these resources. For example, if you are using Helm charts to deploy in production, you can use the same tools in the CI pipeline by modifying the deploy_gke.sh file.
You can also deploy additional GCP resources, such as Cloud SQL and PubSub resources, by modifying the deploy_resources function in the deploy_gke.sh script.
Conclusion
Testing your application in a production-like environment—before actually releasing it to production—allows you to catch the bugs/edge cases early on in the development lifecycle. Kubernetes lets you set up ephemeral test environments via an isolated cluster for each merge request raised or via a shared cluster where each version is isolated via namespaces.
There are pros and cons to using each approach. On the one hand, you get complete isolation in isolated clusters, but they are not very cost-effective and can quickly lead to the proliferation of clusters in a somewhat large development team. However, if you work in an industry where you need isolation for compliance, then a shared cluster is simply not an option.
The shared cluster approach is best suited to scenarios where there are no compliance requirements, as it is cost-effective and utilizes the underlying hardware better.
So, if you are using Kubernetes for ephemeral environments, go ahead and choose the shared cluster approach, as long as you have no regulatory or compliance requirements.